17 September, 2021
Up To Date Implementing An Azure Data Solution DP-200 Practice Test
We provide real DP-200 exam questions and answers braindumps in two formats. Download PDF & Practice Tests. Pass Microsoft DP-200 Exam quickly & easily. The DP-200 PDF type is available for reading and printing. You can print more and practice many times. With the help of our Microsoft DP-200 dumps pdf and vce product and material, you can easily pass the DP-200 exam.
Also have DP-200 free dumps questions for you:
Question 1
- (Exam Topic 1)
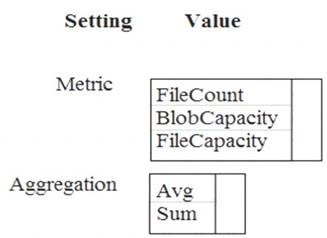
You need to ensure phone-based polling data upload reliability requirements are met. How should you configure monitoring? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
Box 1: FileCapacity
FileCapacity is the amount of storage used by the storage account’s File service in bytes. Box 2: Avg
The aggregation type of the FileCapacity metric is Avg.
Scenario:
All services and processes must be resilient to a regional Azure outage.
All Azure services must be monitored by using Azure Monitor. On-premises SQL Server performance must be monitored.
References:
https://docs.microsoft.com/en-us/azure/azure-monitor/platform/metrics-supported
Does this meet the goal?
You need to ensure phone-based polling data upload reliability requirements are met. How should you configure monitoring? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
Box 1: FileCapacity
FileCapacity is the amount of storage used by the storage account’s File service in bytes. Box 2: Avg
The aggregation type of the FileCapacity metric is Avg.
Scenario:
All services and processes must be resilient to a regional Azure outage.
All Azure services must be monitored by using Azure Monitor. On-premises SQL Server performance must be monitored.
References:
https://docs.microsoft.com/en-us/azure/azure-monitor/platform/metrics-supported
Does this meet the goal?

Question 2
- (Exam Topic 1)
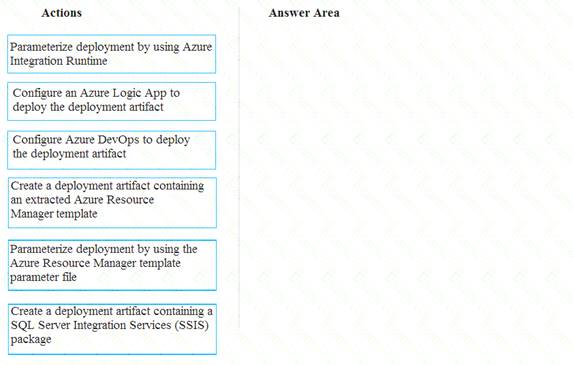
You need to ensure that phone-based polling data can be analyzed in the PollingData database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer are and arrange them in the correct order.
Solution:

Scenario:
All deployments must be performed by using Azure DevOps. Deployments must use templates used in multiple environments
No credentials or secrets should be used during deployments
Does this meet the goal?
You need to ensure that phone-based polling data can be analyzed in the PollingData database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer are and arrange them in the correct order.
Solution:
Scenario:
All deployments must be performed by using Azure DevOps. Deployments must use templates used in multiple environments
No credentials or secrets should be used during deployments
Does this meet the goal?
Question 3
- (Exam Topic 3)
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure
HDInsight. Batch processing will run daily and must: Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale. Solution: Download Azure HDInsight cluster logs by using Azure PowerShell.
Does the solution meet the goal?
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure
HDInsight. Batch processing will run daily and must: Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale. Solution: Download Azure HDInsight cluster logs by using Azure PowerShell.
Does the solution meet the goal?
Question 4
- (Exam Topic 3)
A company is planning to use Microsoft Azure Cosmos DB as the data store for an application. You have the following Azure CLI command:
az cosmosdb create -–name "cosmosdbdev1" –-resource-group "rgdev"
You need to minimize latency and expose the SQL API. How should you complete the command? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Solution:
Box 1: Eventual
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
The following image shows the different consistency levels as a spectrum.

Box 2: GlobalDocumentDB
Select Core(SQL) to create a document database and query by using SQL syntax.
Note: The API determines the type of account to create. Azure Cosmos DB provides five APIs: Core(SQL) and MongoDB for document databases, Gremlin for graph databases, Azure Table, and Cassandra.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels https://docs.microsoft.com/en-us/azure/cosmos-db/create-sql-api-dotnet
Does this meet the goal?
A company is planning to use Microsoft Azure Cosmos DB as the data store for an application. You have the following Azure CLI command:
az cosmosdb create -–name "cosmosdbdev1" –-resource-group "rgdev"
You need to minimize latency and expose the SQL API. How should you complete the command? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
Box 1: Eventual
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
The following image shows the different consistency levels as a spectrum.
Box 2: GlobalDocumentDB
Select Core(SQL) to create a document database and query by using SQL syntax.
Note: The API determines the type of account to create. Azure Cosmos DB provides five APIs: Core(SQL) and MongoDB for document databases, Gremlin for graph databases, Azure Table, and Cassandra.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels https://docs.microsoft.com/en-us/azure/cosmos-db/create-sql-api-dotnet
Does this meet the goal?
Question 5
- (Exam Topic 3)
You plan to create a new single database instance of Microsoft Azure SQL Database.
The database must only allow communication from the data engineer’s workstation. You must connect directly to the instance by using Microsoft SQL Server Management Studio.
You need to create and configure the Database. Which three Azure PowerShell cmdlets should you use to develop the solution? To answer, move the appropriate cmdlets from the list of cmdlets to the answer area and arrange them in the correct order.

Solution:
Step 1: New-AzureSqlServer Create a server.
Step 2: New-AzureRmSqlServerFirewallRule
New-AzureRmSqlServerFirewallRule creates a firewall rule for a SQL Database server. Can be used to create a server firewall rule that allows access from the specified IP range. Step 3: New-AzureRmSqlDatabase
Example: Create a database on a specified server
PS C:>New-AzureRmSqlDatabase -ResourceGroupName "ResourceGroup01" -ServerName "Server01"
-DatabaseName "Database01
References:
https://docs.microsoft.com/en-us/azure/sql-database/scripts/sql-database-create-and-configure-database-powersh
Does this meet the goal?
You plan to create a new single database instance of Microsoft Azure SQL Database.
The database must only allow communication from the data engineer’s workstation. You must connect directly to the instance by using Microsoft SQL Server Management Studio.
You need to create and configure the Database. Which three Azure PowerShell cmdlets should you use to develop the solution? To answer, move the appropriate cmdlets from the list of cmdlets to the answer area and arrange them in the correct order.
Solution:
Step 1: New-AzureSqlServer Create a server.
Step 2: New-AzureRmSqlServerFirewallRule
New-AzureRmSqlServerFirewallRule creates a firewall rule for a SQL Database server. Can be used to create a server firewall rule that allows access from the specified IP range. Step 3: New-AzureRmSqlDatabase
Example: Create a database on a specified server
PS C:>New-AzureRmSqlDatabase -ResourceGroupName "ResourceGroup01" -ServerName "Server01"
-DatabaseName "Database01
References:
https://docs.microsoft.com/en-us/azure/sql-database/scripts/sql-database-create-and-configure-database-powersh
Does this meet the goal?
Question 6
- (Exam Topic 2)
You need to set up access to Azure SQL Database for Tier 7 and Tier 8 partners.
Which three actions should you perform in sequence? To answer, move the appropriate three actions from the list of actions to the answer area and arrange them in the correct order.

Solution:
Tier 7 and 8 data access is constrained to single endpoints managed by partners for access Step 1: Set the Allow Azure Services to Access Server setting to Disabled
Set Allow access to Azure services to OFF for the most secure configuration.
By default, access through the SQL Database firewall is enabled for all Azure services, under Allow access to Azure services. Choose OFF to disable access for all Azure services.
Note: The firewall pane has an ON/OFF button that is labeled Allow access to Azure services. The ON setting allows communications from all Azure IP addresses and all Azure subnets. These Azure IPs or subnets might not be owned by you. This ON setting is probably more open than you want your SQL Database to be. The virtual network rule feature offers much finer granular control.
Step 2: In the Azure portal, create a server firewall rule Set up SQL Database server firewall rules
Server-level IP firewall rules apply to all databases within the same SQL Database server. To set up a server-level firewall rule:
 In Azure portal, select SQL databases from the left-hand menu, and select your database on the SQL databases page.
In Azure portal, select SQL databases from the left-hand menu, and select your database on the SQL databases page.
 On the Overview page, select Set server firewall. The Firewall settings page for the database server opens.
On the Overview page, select Set server firewall. The Firewall settings page for the database server opens.
Step 3: Connect to the database and use Transact-SQL to create a database firewall rule
Database-level firewall rules can only be configured using Transact-SQL (T-SQL) statements, and only after you've configured a server-level firewall rule.
To setup a database-level firewall rule:
 In Object Explorer, right-click the database and select New Query.
In Object Explorer, right-click the database and select New Query.
EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4';
On the toolbar, select Execute to create the firewall rule. References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-security-tutorial
Does this meet the goal?
You need to set up access to Azure SQL Database for Tier 7 and Tier 8 partners.
Which three actions should you perform in sequence? To answer, move the appropriate three actions from the list of actions to the answer area and arrange them in the correct order.
Solution:
Tier 7 and 8 data access is constrained to single endpoints managed by partners for access Step 1: Set the Allow Azure Services to Access Server setting to Disabled
Set Allow access to Azure services to OFF for the most secure configuration.
By default, access through the SQL Database firewall is enabled for all Azure services, under Allow access to Azure services. Choose OFF to disable access for all Azure services.
Note: The firewall pane has an ON/OFF button that is labeled Allow access to Azure services. The ON setting allows communications from all Azure IP addresses and all Azure subnets. These Azure IPs or subnets might not be owned by you. This ON setting is probably more open than you want your SQL Database to be. The virtual network rule feature offers much finer granular control.
Step 2: In the Azure portal, create a server firewall rule Set up SQL Database server firewall rules
Server-level IP firewall rules apply to all databases within the same SQL Database server. To set up a server-level firewall rule:
In Azure portal, select SQL databases from the left-hand menu, and select your database on the SQL databases page. On the Overview page, select Set server firewall. The Firewall settings page for the database server opens.Step 3: Connect to the database and use Transact-SQL to create a database firewall rule
Database-level firewall rules can only be configured using Transact-SQL (T-SQL) statements, and only after you've configured a server-level firewall rule.
To setup a database-level firewall rule:
In Object Explorer, right-click the database and select New Query.EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4'; On the toolbar, select Execute to create the firewall rule. References:https://docs.microsoft.com/en-us/azure/sql-database/sql-database-security-tutorial
Does this meet the goal?
Question 7
- (Exam Topic 3)
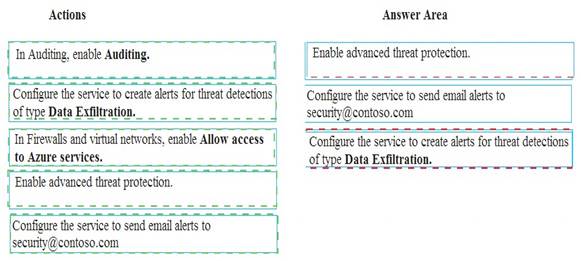
A company uses Microsoft Azure SQL Database to store sensitive company data. You encrypt the data and only allow access to specified users from specified locations.
You must monitor data usage, and data copied from the system to prevent data leakage.
You need to configure Azure SQL Database to email a specific user when data leakage occurs.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Solution:
Does this meet the goal?
A company uses Microsoft Azure SQL Database to store sensitive company data. You encrypt the data and only allow access to specified users from specified locations.
You must monitor data usage, and data copied from the system to prevent data leakage.
You need to configure Azure SQL Database to email a specific user when data leakage occurs.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Solution:
Does this meet the goal?
Question 8
- (Exam Topic 3)
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Configure Azure Data Late Storage diagnostics to store logs and metrics in a storage account. Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Configure Azure Data Late Storage diagnostics to store logs and metrics in a storage account. Does the solution meet the goal?
Question 9
- (Exam Topic 3)
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
Question 10
- (Exam Topic 3)
A company plans to analyze a continuous flow of data from a social media platform by using Microsoft Azure Stream Analytics. The incoming data is formatted as one record per row.
You need to create the input stream.
How should you complete the REST API segment? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.


Solution:

Does this meet the goal?
A company plans to analyze a continuous flow of data from a social media platform by using Microsoft Azure Stream Analytics. The incoming data is formatted as one record per row.
You need to create the input stream.
How should you complete the REST API segment? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
Does this meet the goal?
Question 11
- (Exam Topic 3)
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution contains a dedicated database for each customer organization. Customer organizations have peak usage at different periods during the year.
You need to implement the Azure SQL Database elastic pool to minimize cost. Which option or options should you configure?
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution contains a dedicated database for each customer organization. Customer organizations have peak usage at different periods during the year.
You need to implement the Azure SQL Database elastic pool to minimize cost. Which option or options should you configure?
 Maximum resources utilized by all databases in the pool (either maximum DTUs or maximum vCores depending on your choice of resourcing model).
Maximum resources utilized by all databases in the pool (either maximum DTUs or maximum vCores depending on your choice of resourcing model).
Question 12
- (Exam Topic 3)
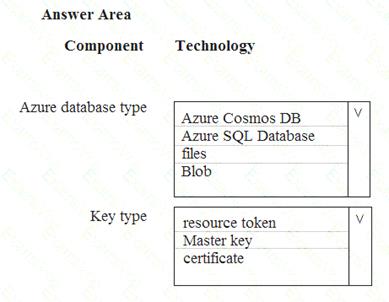
You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have the following code:
Which database and authorization types are used? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
Box 1: Azure Cosmos DB
The DocumentClient.CreateDatabaseAsync(Database, RequestOptions) method creates a database resource as an asychronous operation in the Azure Cosmos DB service.
Box 2: Master Key
Azure Cosmos DB uses two types of keys to authenticate users and provide access to its data and resources: Master Key, Resource Tokens
Master keys provide access to the all the administrative resources for the database account. Master keys: Provide access to accounts, databases, users, and permissions.
Provide access to accounts, databases, users, and permissions.
 Cannot be used to provide granular access to containers and documents.
Cannot be used to provide granular access to containers and documents.
Are created during the creation of an account.
Can be regenerated at any time.
Does this meet the goal?
You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have the following code:
Which database and authorization types are used? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
Box 1: Azure Cosmos DB
The DocumentClient.CreateDatabaseAsync(Database, RequestOptions) method creates a database resource as an asychronous operation in the Azure Cosmos DB service.
Box 2: Master Key
Azure Cosmos DB uses two types of keys to authenticate users and provide access to its data and resources: Master Key, Resource Tokens
Master keys provide access to the all the administrative resources for the database account. Master keys:
Provide access to accounts, databases, users, and permissions. Cannot be used to provide granular access to containers and documents. Are created during the creation of an account. Can be regenerated at any time.Does this meet the goal?
Question 13
- (Exam Topic 3)
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of 250 web servers generates approximately gigabytes (GB) of log data each day. All log data is stored in a single folder in Microsoft Azure Data Lake Storage Gen 2.
You need to improve the performance of the process.
Which two changes should you make? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of 250 web servers generates approximately gigabytes (GB) of log data each day. All log data is stored in a single folder in Microsoft Azure Data Lake Storage Gen 2.
You need to improve the performance of the process.
Which two changes should you make? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
Question 14
- (Exam Topic 3)
A company is deploying a service-based data environment. You are developing a solution to process this data. The solution must meet the following requirements:
Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service
Use an Azure Data Lake Storage account to store processed data
Allow users to download processed data
You need to recommend technologies for the solution.
Which technologies should you use? To answer, select the appropriate options in the answer area.
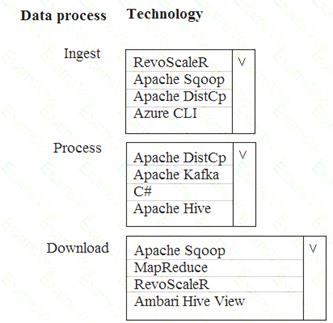
Solution:
Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
Azure HDInsight is a cloud distribution of the Hadoop components from the Hortonworks Data Platform (HDP).
Does this meet the goal?
A company is deploying a service-based data environment. You are developing a solution to process this data. The solution must meet the following requirements:
Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service Use an Azure Data Lake Storage account to store processed data Allow users to download processed dataYou need to recommend technologies for the solution.
Which technologies should you use? To answer, select the appropriate options in the answer area.
Solution:
Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
Azure HDInsight is a cloud distribution of the Hadoop components from the Hortonworks Data Platform (HDP).
Does this meet the goal?
Question 15
- (Exam Topic 3)
You implement an event processing solution using Microsoft Azure Stream Analytics. The solution must meet the following requirements:
•Ingest data from Blob storage
• Analyze data in real time
•Store processed data in Azure Cosmos DB
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Solution:
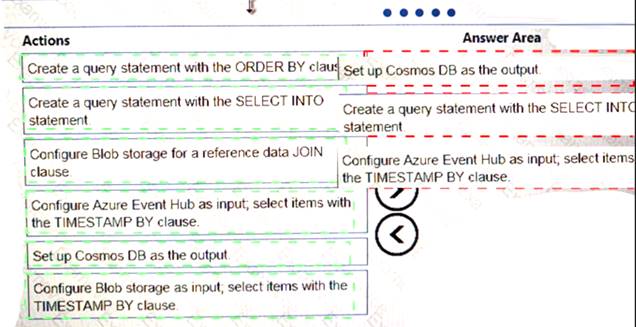
Does this meet the goal?
You implement an event processing solution using Microsoft Azure Stream Analytics. The solution must meet the following requirements:
•Ingest data from Blob storage
• Analyze data in real time
•Store processed data in Azure Cosmos DB
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Solution:
Does this meet the goal?
Question 16
- (Exam Topic 3)
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Solution:
Step 1: Create an HDInisght cluster with the Spark cluster type Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table. Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter
Step 5: Load the hvac table into Power BI Desktop
You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data. References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
Does this meet the goal?
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Solution:
Step 1: Create an HDInisght cluster with the Spark cluster type Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table. Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter
Step 5: Load the hvac table into Power BI Desktop
You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data. References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
Does this meet the goal?
Question 17
- (Exam Topic 3)
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Create an Azure Automation runbook to copy events. Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Create an Azure Automation runbook to copy events. Does the solution meet the goal?
Question 18
- (Exam Topic 3)
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Use Azure Data Factory to convert the parquet files to CSV files
2. Create an external data source pointing to the Azure storage account
3. Create an external file format and external table using the external data source
4. Load the data using the INSERT…SELECT statement Does the solution meet the goal?
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Use Azure Data Factory to convert the parquet files to CSV files
2. Create an external data source pointing to the Azure storage account
3. Create an external file format and external table using the external data source
4. Load the data using the INSERT…SELECT statement Does the solution meet the goal?
Question 19
- (Exam Topic 3)
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure
HDInsight. Batch processing will run daily and must: Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale. Solution: Monitor cluster load using the Ambari Web UI.
Does the solution meet the goal?
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure
HDInsight. Batch processing will run daily and must: Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale. Solution: Monitor cluster load using the Ambari Web UI.
Does the solution meet the goal?
Question 20
- (Exam Topic 3)
You are developing the data platform for a global retail company. The company operates during normal working hours in each region. The analytical database is used once a week for building sales projections.
Each region maintains its own private virtual network.
Building the sales projections is very resource intensive are generates upwards of 20 terabytes (TB) of data. Microsoft Azure SQL Databases must be provisioned.
 Database provisioning must maximize performance and minimize cost
Database provisioning must maximize performance and minimize cost
The daily sales for each region must be stored in an Azure SQL Database instance
Once a day, the data for all regions must be loaded in an analytical Azure SQL Database instance You need to provision Azure SQL database instances.
How should you provision the database instances? To answer, drag the appropriate Azure SQL products to the correct databases. Each Azure SQL product may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Solution:
Box 1: Azure SQL Database elastic pools
SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure
SQL Database server and share a set number of resources at a set price. Elastic pools in Azure SQL Database enable SaaS developers to optimize the price performance for a group of databases within a prescribed budget while delivering performance elasticity for each database.
Box 2: Azure SQL Database Hyperscale
A Hyperscale database is an Azure SQL database in the Hyperscale service tier that is backed by the Hyperscale scale-out storage technology. A Hyperscale database supports up to 100 TB of data and provides high throughput and performance, as well as rapid scaling to adapt to the workload requirements. Scaling is transparent to the application – connectivity, query processing, and so on, work like any other SQL database.
Does this meet the goal?
You are developing the data platform for a global retail company. The company operates during normal working hours in each region. The analytical database is used once a week for building sales projections.
Each region maintains its own private virtual network.
Building the sales projections is very resource intensive are generates upwards of 20 terabytes (TB) of data. Microsoft Azure SQL Databases must be provisioned.
Database provisioning must maximize performance and minimize cost The daily sales for each region must be stored in an Azure SQL Database instance Once a day, the data for all regions must be loaded in an analytical Azure SQL Database instance You need to provision Azure SQL database instances.How should you provision the database instances? To answer, drag the appropriate Azure SQL products to the correct databases. Each Azure SQL product may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Solution:
Box 1: Azure SQL Database elastic pools
SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure
SQL Database server and share a set number of resources at a set price. Elastic pools in Azure SQL Database enable SaaS developers to optimize the price performance for a group of databases within a prescribed budget while delivering performance elasticity for each database.
Box 2: Azure SQL Database Hyperscale
A Hyperscale database is an Azure SQL database in the Hyperscale service tier that is backed by the Hyperscale scale-out storage technology. A Hyperscale database supports up to 100 TB of data and provides high throughput and performance, as well as rapid scaling to adapt to the workload requirements. Scaling is transparent to the application – connectivity, query processing, and so on, work like any other SQL database.
Does this meet the goal?
Question 21
- (Exam Topic 2)
You need to process and query ingested Tier 9 data.
Which two options should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to process and query ingested Tier 9 data.
Which two options should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.

Question 22
- (Exam Topic 3)
Your company uses several Azure HDInsight clusters.
The data engineering team reports several errors with some application using these clusters. You need to recommend a solution to review the health of the clusters.
What should you include in you recommendation?
Your company uses several Azure HDInsight clusters.
The data engineering team reports several errors with some application using these clusters. You need to recommend a solution to review the health of the clusters.
What should you include in you recommendation?
Question 23
- (Exam Topic 3)
A company runs Microsoft Dynamics CRM with Microsoft SQL Server on-premises. SQL Server Integration Services (SSIS) packages extract data from Dynamics CRM APIs, and load the data into a SQL Server data warehouse.
The datacenter is running out of capacity. Because of the network configuration, you must extract on premises data to the cloud over https. You cannot open any additional ports. The solution must implement the least amount of effort.
You need to create the pipeline system.
Which component should you use? To answer, select the appropriate technology in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
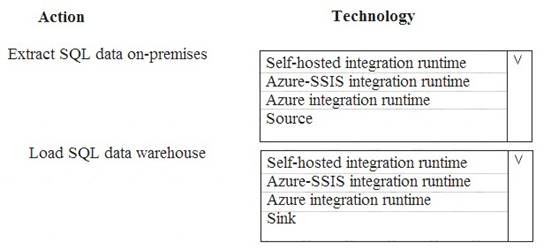
Solution:
Box 1: Source
For Copy activity, it requires source and sink linked services to define the direction of data flow. Copying between a cloud data source and a data source in private network: if either source or sink linked
service points to a self-hosted IR, the copy activity is executed on that self-hosted Integration Runtime.
Box 2: Self-hosted integration runtime
A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on-premises machine or a virtual machine (VM) inside a private network.
References:
https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
Does this meet the goal?
A company runs Microsoft Dynamics CRM with Microsoft SQL Server on-premises. SQL Server Integration Services (SSIS) packages extract data from Dynamics CRM APIs, and load the data into a SQL Server data warehouse.
The datacenter is running out of capacity. Because of the network configuration, you must extract on premises data to the cloud over https. You cannot open any additional ports. The solution must implement the least amount of effort.
You need to create the pipeline system.
Which component should you use? To answer, select the appropriate technology in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
Box 1: Source
For Copy activity, it requires source and sink linked services to define the direction of data flow. Copying between a cloud data source and a data source in private network: if either source or sink linked
service points to a self-hosted IR, the copy activity is executed on that self-hosted Integration Runtime.
Box 2: Self-hosted integration runtime
A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on-premises machine or a virtual machine (VM) inside a private network.
References:
https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
Does this meet the goal?
Question 24
- (Exam Topic 3)
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Use information stored m Azure Active Directory reports.
Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Use information stored m Azure Active Directory reports.
Does the solution meet the goal?