21 January, 2024
Virtual Databricks Databricks-Certified-Data-Analyst-Associate Braindump Online
we provide Simulation Databricks Databricks-Certified-Data-Analyst-Associate test question which are the best for clearing Databricks-Certified-Data-Analyst-Associate test, and to get certified by Databricks Databricks Certified Data Analyst Associate Exam. The Databricks-Certified-Data-Analyst-Associate Questions & Answers covers all the knowledge points of the real Databricks-Certified-Data-Analyst-Associate exam. Crack your Databricks Databricks-Certified-Data-Analyst-Associate Exam with latest dumps, guaranteed!
Question 1
Which of the following benefits of using Databricks SQL is provided by Data Explorer?

Question 2
Which of the following describes how Databricks SQL should be used in relation to other
business intelligence (BI) tools like Tableau, Power BI, and looker?
business intelligence (BI) tools like Tableau, Power BI, and looker?
Question 3
A data analyst is processing a complex aggregation on a table with zero null values and their query returns the following result:
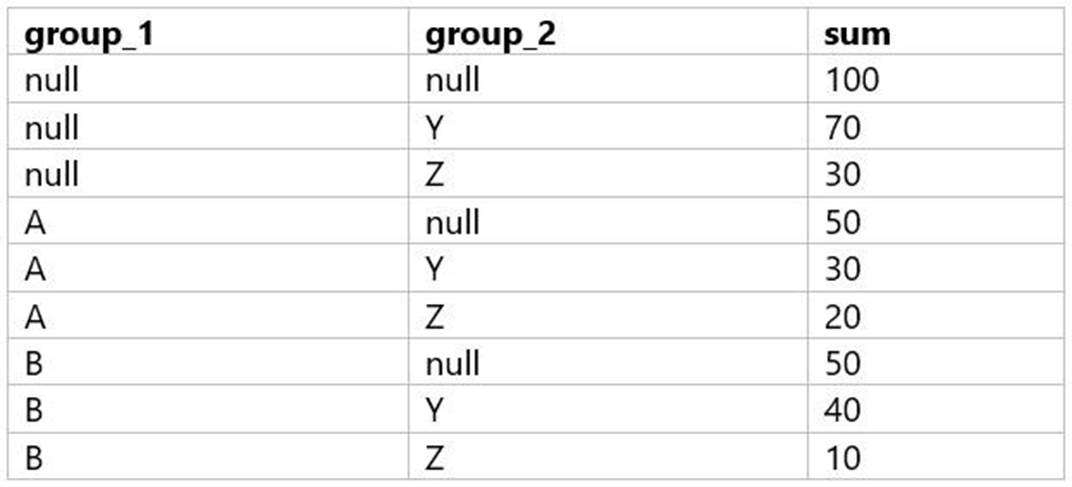
Which of the following queries did the analyst run to obtain the above result?
A)

B)

C)

D)

E)

Which of the following queries did the analyst run to obtain the above result?
A)
B)
C)
D)
E)
Question 4
Which of the following layers of the medallion architecture is most commonly used by data analysts?
Question 5
A data analyst is working with gold-layer tables to complete an ad-hoc project. A stakeholder has provided the analyst with an additional dataset that can be used to augment the gold-layer tables already in use.
Which of the following terms is used to describe this data augmentation?
Which of the following terms is used to describe this data augmentation?
Question 6
Which of the following is a benefit of Databricks SQL using ANSI SQL as its standard SQL dialect?
Question 7
A data analyst is attempting to drop a table my_table. The analyst wants to delete all table metadata and data.
They run the following command: DROP TABLE IF EXISTS my_table;
While the object no longer appears when they run SHOW TABLES, the data files still exist.
Which of the following describes why the data files still exist and the metadata files were deleted?
They run the following command: DROP TABLE IF EXISTS my_table;
While the object no longer appears when they run SHOW TABLES, the data files still exist.
Which of the following describes why the data files still exist and the metadata files were deleted?
Question 8
A data analyst has been asked to provide a list of options on how to share a dashboard with a client. It is a security requirement that the client does not gain access to any other information, resources, or artifacts in the database.
Which of the following approaches cannot be used to share the dashboard and meet the security requirement?
Which of the following approaches cannot be used to share the dashboard and meet the security requirement?
Question 9
A data analyst has created a user-defined function using the following line of code: CREATE FUNCTION price(spend DOUBLE, units DOUBLE)
RETURNS DOUBLE
RETURN spend / units;
Which of the following code blocks can be used to apply this function to the customer_spend and customer_units columns of the table customer_summary to create column customer_price?
RETURNS DOUBLE
RETURN spend / units;
Which of the following code blocks can be used to apply this function to the customer_spend and customer_units columns of the table customer_summary to create column customer_price?
Question 10
Delta Lake stores table data as a series of data files, but it also stores a lot of other information.
Which of the following is stored alongside data files when using Delta Lake?
Which of the following is stored alongside data files when using Delta Lake?
Question 11
Which of the following statements about adding visual appeal to visualizations in the Visualization Editor is incorrect?
Question 12
Which of the following statements about a refresh schedule is incorrect?
Question 13
The stakeholders.customers table has 15 columns and 3,000 rows of data. The following command is run:
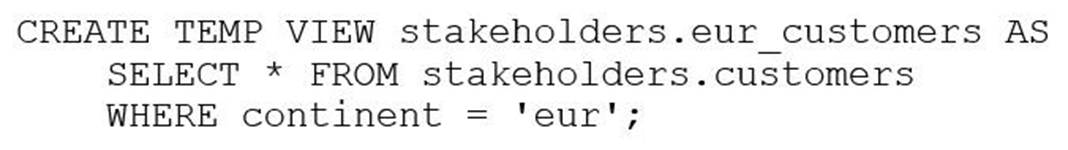
After runningSELECT * FROM stakeholders.eur_customers, 15 rows are returned. After the command executes completely, the user logs out of Databricks.
After logging back in two days later, what is the status of thestakeholders.eur_customersview?
After runningSELECT * FROM stakeholders.eur_customers, 15 rows are returned. After the command executes completely, the user logs out of Databricks.
After logging back in two days later, what is the status of thestakeholders.eur_customersview?
Question 14
Which of the following should data analysts consider when working with personally identifiable information (PII) data?