29 December, 2019
Vivid Microsoft 70-776 Cram
Your success in Microsoft 70-776 is our sole target and we develop all our 70-776 braindumps in a way that facilitates the attainment of this target. Not only is our 70-776 study material the best you can find, it is also the most detailed and the most updated. 70-776 Practice Exams for Microsoft {category} 70-776 are written to the highest standards of technical accuracy.
Question 1
You have an on-premises Microsoft SQL Server instance.
You plan to copy a table from the instance to a Microsoft Azure Storage account. You need to ensure that you can copy the table by using Azure Data Factory. Which service should you deploy?
You plan to copy a table from the instance to a Microsoft Azure Storage account. You need to ensure that you can copy the table by using Azure Data Factory. Which service should you deploy?

Question 2
DRAG DROP
You have a Microsoft Azure SQL data warehouse named DW1. Data is located to DW1 once daily at 01:00.
A user accidentally deletes data from a fact table in DW1 at 09:00.
You need to recover the lost data. The solution must prevent the need to change any connection strings and must minimize downtime.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
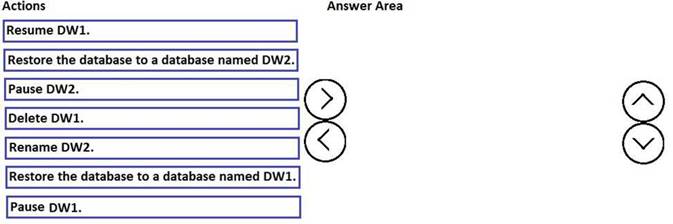
Solution:
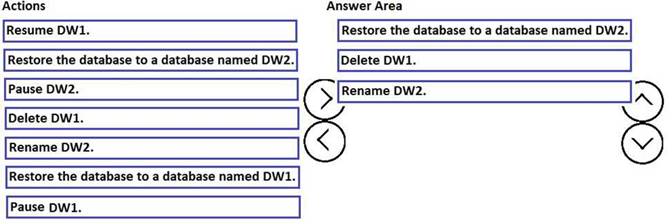
Does this meet the goal?
You have a Microsoft Azure SQL data warehouse named DW1. Data is located to DW1 once daily at 01:00.
A user accidentally deletes data from a fact table in DW1 at 09:00.
You need to recover the lost data. The solution must prevent the need to change any connection strings and must minimize downtime.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Solution:
Does this meet the goal?
Question 3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You change the table to use a column that is not skewed for hash distribution. Does this meet the goal?
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You change the table to use a column that is not skewed for hash distribution. Does this meet the goal?
Question 4
DRAG DROP
You need to copy data from Microsoft Azure SQL Database to Azure Data Lake Store by using Azure Data Factory.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
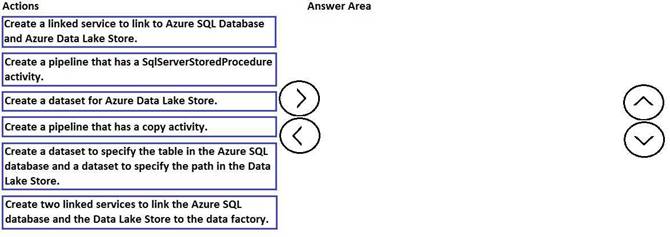
Solution:
References:
https://docs.microsoft.com/en-us/azure/data-factory/copy-activity-overview
Does this meet the goal?
You need to copy data from Microsoft Azure SQL Database to Azure Data Lake Store by using Azure Data Factory.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Solution:
References:
https://docs.microsoft.com/en-us/azure/data-factory/copy-activity-overview
Does this meet the goal?
Question 5
DRAG DROP
You have a Microsoft Azure Stream Analytics solution that captures website visits and user interactions on the website.
You have the sample input data described in the following table.

You have the sample output described in the following table.

How should you complete the script? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
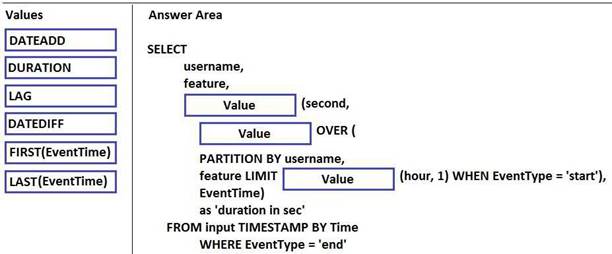
Solution:
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-stream-analytics-query- patterns
Does this meet the goal?
You have a Microsoft Azure Stream Analytics solution that captures website visits and user interactions on the website.
You have the sample input data described in the following table.
You have the sample output described in the following table.
How should you complete the script? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Solution:
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-stream-analytics-query- patterns
Does this meet the goal?
Question 6
You have a file in a Microsoft Azure Data Lake Store that contains sales data. The file contains sales amounts by salesperson, by city, and by state.
You need to use U-SQL to calculate the percentage of sales that each city has for its respective state. Which code should you use?


You need to use U-SQL to calculate the percentage of sales that each city has for its respective state. Which code should you use?
Question 7
You have a Microsoft Azure Data Lake Store and an Azure Active Directory tenant.
You are developing an application that will access the Data Lake Store by using end-user credentials. You need to ensure that the application uses end-user authentication to access the Data Lake Store. What should you create?
You are developing an application that will access the Data Lake Store by using end-user credentials. You need to ensure that the application uses end-user authentication to access the Data Lake Store. What should you create?
Question 8
You have a Microsoft Azure Data Lake Analytics service.
You have a CSV file that contains employee salaries.
You need to write a U-SQL query to load the file and to extract all the employees who earn salaries that are greater than $100,000. You must encapsulate the data for reuse.
What should you use?
You have a CSV file that contains employee salaries.
You need to write a U-SQL query to load the file and to extract all the employees who earn salaries that are greater than $100,000. You must encapsulate the data for reuse.
What should you use?
Question 9
HOTSPOT
You have a Microsoft Azure Data Lake Analytics service.
You have a file named Employee.tsv that contains data on employees. Employee.tsv contains seven columns named EmpId, Start, FirstName, LastName, Age, Department, and Title.
You need to create a Data Lake Analytics jobs to transform Employee.tsv, define a schema for the data, and output the data to a CSV file. The outputted data must contain only employees who are in the sales department. The Age column must allow NULL.
How should you complete the U-SQL code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
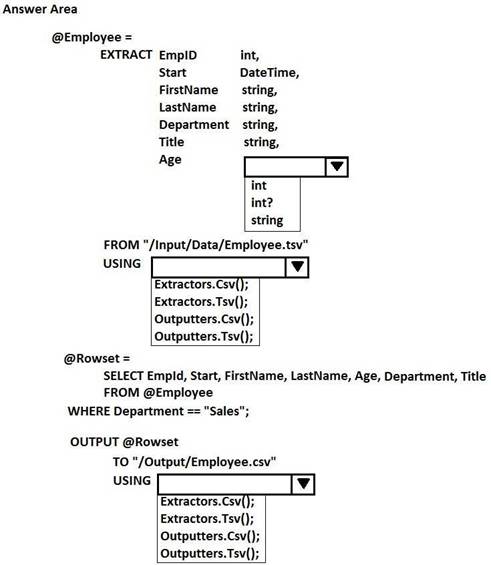
Solution:
References:
https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-u-sql-get-started
Does this meet the goal?
You have a Microsoft Azure Data Lake Analytics service.
You have a file named Employee.tsv that contains data on employees. Employee.tsv contains seven columns named EmpId, Start, FirstName, LastName, Age, Department, and Title.
You need to create a Data Lake Analytics jobs to transform Employee.tsv, define a schema for the data, and output the data to a CSV file. The outputted data must contain only employees who are in the sales department. The Age column must allow NULL.
How should you complete the U-SQL code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
References:
https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-u-sql-get-started
Does this meet the goal?
Question 10
DRAG DROP
You need to create a linked service in Microsoft Azure Data Factory. The linked service must use an Azure Database for MySQL table named Customers.
How should you complete the JSON snippet? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Solution:

Does this meet the goal?
You need to create a linked service in Microsoft Azure Data Factory. The linked service must use an Azure Database for MySQL table named Customers.
How should you complete the JSON snippet? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Solution:
Does this meet the goal?
Question 11
DRAG DROP
You are designing a Microsoft Azure analytics solution. The solution requires that data be copied from Azure Blob storage to Azure Data Lake Store.
The data will be copied on a recurring schedule. Occasionally, the data will be copied manually. You need to recommend a solution to copy the data.
Which tools should you include in the recommendation? To answer, drag the appropriate tools to the correct requirements. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Solution:

Does this meet the goal?
You are designing a Microsoft Azure analytics solution. The solution requires that data be copied from Azure Blob storage to Azure Data Lake Store.
The data will be copied on a recurring schedule. Occasionally, the data will be copied manually. You need to recommend a solution to copy the data.
Which tools should you include in the recommendation? To answer, drag the appropriate tools to the correct requirements. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Solution:
Does this meet the goal?
Question 12
You have sensor devices that report data to Microsoft Azure Stream Analytics. Each sensor reports data several times per second.
You need to create a live dashboard in Microsoft Power BI that shows the performance of the sensor devices. The solution must minimize lag when visualizing the data.
Which function should you use for the time-series data element?
You need to create a live dashboard in Microsoft Power BI that shows the performance of the sensor devices. The solution must minimize lag when visualizing the data.
Which function should you use for the time-series data element?
Question 13
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.

You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You add a structure property to the dataset.
Does this meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.
You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You add a structure property to the dataset.
Does this meet the goal?
Question 14
You manage an on-premises data warehouse that uses Microsoft SQL Server. The data warehouse contains 100 TB of data. The data is partitioned by month. One TB of data is added to the data warehouse each month.
You create a Microsoft Azure SQL data warehouse and copy the on-premises data to the data warehouse.
You need to implement a process to replicate the on-premises data warehouse to the Azure SQL data warehouse. The solution must support daily incremental updates and must provide error handling. What should you use?
You create a Microsoft Azure SQL data warehouse and copy the on-premises data to the data warehouse.
You need to implement a process to replicate the on-premises data warehouse to the Azure SQL data warehouse. The solution must support daily incremental updates and must provide error handling. What should you use?
Question 15
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a table named Table1 that contains 3 billion rows. Table1 contains data from the last 36 months.
At the end of every month, the oldest month of data is removed based on a column named DateTime.
You need to minimize how long it takes to remove the oldest month of data. Solution: You implement a columnstore index on the DateTime column. Does this meet the goal?
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a table named Table1 that contains 3 billion rows. Table1 contains data from the last 36 months.
At the end of every month, the oldest month of data is removed based on a column named DateTime.
You need to minimize how long it takes to remove the oldest month of data. Solution: You implement a columnstore index on the DateTime column. Does this meet the goal?
Question 16
You have a Microsoft Azure Data Lake Analytics service.
You need to provide a user with the ability to monitor Data Lake Analytics jobs. The solution must minimize the number of permissions assigned to the user.
Which role should you assign to the user?
You need to provide a user with the ability to monitor Data Lake Analytics jobs. The solution must minimize the number of permissions assigned to the user.
Which role should you assign to the user?
Question 17
You have a Microsoft Azure Data Lake Analytics service. You plan to configure diagnostic logging.
You need to use Microsoft Operations Management Suite (OMS) to monitor the IP addresses that are used to access the Data Lake Store.
What should you do?
You need to use Microsoft Operations Management Suite (OMS) to monitor the IP addresses that are used to access the Data Lake Store.
What should you do?
Question 18
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You add a nonclustered columnstore index.
Does this meet the goal?
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You add a nonclustered columnstore index.
Does this meet the goal?
Question 19
You are developing an application that uses Microsoft Azure Stream Analytics.
You have data structures that are defined dynamically.
You want to enable consistency between the logical methods used by stream processing and batch processing.
You need to ensure that the data can be integrated by using consistent data points. What should you use to process the data?
You have data structures that are defined dynamically.
You want to enable consistency between the logical methods used by stream processing and batch processing.
You need to ensure that the data can be integrated by using consistent data points. What should you use to process the data?
Question 20
HOTSPOT
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
How should you configure the storage to archive the source data? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Solution:
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
Does this meet the goal?
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
How should you configure the storage to archive the source data? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Solution:
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
Does this meet the goal?
Question 21
HOTSPOT
You are designing a fact table that has 100 million rows and 1,800 partitions. The partitions are defined based on a column named OrderDayKey. The fact table will contain:
Data from the last five years
A clustered columnstore index
A column named YearMonthKey that stores the year and the month
Multiple transformations will be performed on the fact table during the loading process. The fact table will be hash distributed on a column named OrderId.
You plan to load the data to a staging table and to perform transformations on the staging table. You will then load the data from the staging table to the final fact table.
You need to design a solution to load the data to the fact table. The solution must minimize how long it takes to perform the following tasks:
Load the staging table.
Transfer the data from the staging table to the fact table. Remove data that is older than five years.
Query the data in the fact table
How should you configure the tables? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
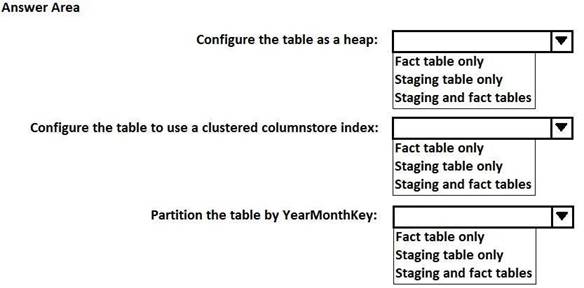
Solution:
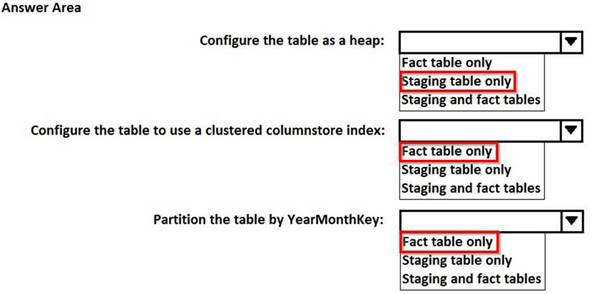
Does this meet the goal?
You are designing a fact table that has 100 million rows and 1,800 partitions. The partitions are defined based on a column named OrderDayKey. The fact table will contain:
Data from the last five years
A clustered columnstore index
A column named YearMonthKey that stores the year and the month
Multiple transformations will be performed on the fact table during the loading process. The fact table will be hash distributed on a column named OrderId.
You plan to load the data to a staging table and to perform transformations on the staging table. You will then load the data from the staging table to the final fact table.
You need to design a solution to load the data to the fact table. The solution must minimize how long it takes to perform the following tasks:
Load the staging table.
Transfer the data from the staging table to the fact table. Remove data that is older than five years.
Query the data in the fact table
How should you configure the tables? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Solution:
Does this meet the goal?
Question 22
HOTSPOT
You use Microsoft Visual Studio to develop custom solutions for customers who use Microsoft Azure Data Lake Analytics.
You install the Data Lake Tools for Visual Studio.
You need to identify which tasks can be performed from Visual Studio and which tasks can be performed from the Azure portal.
What should you identify for each task? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
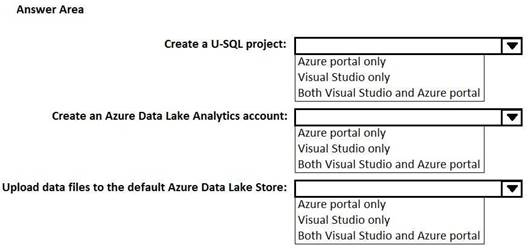
Solution:
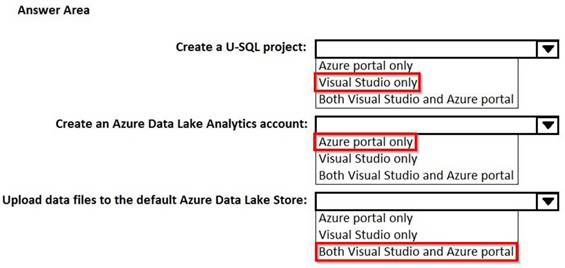
Does this meet the goal?
You use Microsoft Visual Studio to develop custom solutions for customers who use Microsoft Azure Data Lake Analytics.
You install the Data Lake Tools for Visual Studio.
You need to identify which tasks can be performed from Visual Studio and which tasks can be performed from the Azure portal.
What should you identify for each task? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Solution:
Does this meet the goal?
Question 23
You are designing a solution that will use Microsoft Azure Data Lake Store.
You need to recommend a solution to ensure that the storage service is available if a regional outage occurs. The solution must minimize costs.
What should you recommend?
You need to recommend a solution to ensure that the storage service is available if a regional outage occurs. The solution must minimize costs.
What should you recommend?
Question 24
You are building a Microsoft Azure Stream Analytics job definition that includes inputs, queries, and outputs.
You need to create a job that automatically provides the highest level of parallelism to the compute instances.
What should you do?
You need to create a job that automatically provides the highest level of parallelism to the compute instances.
What should you do?
Question 25
You use Microsoft Azure Data Lake Store as the default storage for an Azure HDInsight cluster.
You establish an SSH connection to the HDInsight cluster.
You need to copy files from the HDInsight cluster to the Data LakeStore. Which command should you use?
You establish an SSH connection to the HDInsight cluster.
You need to copy files from the HDInsight cluster to the Data LakeStore. Which command should you use?